事情是这样的
朋友公司的网站首页被挂马了,找我看看。
 打开首页源码发现头部被植入了恶意js。这部分代码设置了页面的标题、关键词和描述,但它们都使用了HTML实体编码(例如 国 代表中文字符“国”),解码后显示的是与产品推广、在线观看、品牌精品、亚洲等内容相关的标题和元信息。这明显是为了吸引用户点击或优化搜索引擎排名,但需要注意的是,内容似乎与朋友公司的主题不符,且含有敏感词汇,可能涉及不当或违规信息。所以必须得清楚。
既然找到木马了,那就找到首页删除就好了。
打开首页源码发现头部被植入了恶意js。这部分代码设置了页面的标题、关键词和描述,但它们都使用了HTML实体编码(例如 国 代表中文字符“国”),解码后显示的是与产品推广、在线观看、品牌精品、亚洲等内容相关的标题和元信息。这明显是为了吸引用户点击或优化搜索引擎排名,但需要注意的是,内容似乎与朋友公司的主题不符,且含有敏感词汇,可能涉及不当或违规信息。所以必须得清楚。
既然找到木马了,那就找到首页删除就好了。
如果事情真的那么简单得话,就不会有这篇文章了
开始我翻遍了整个网站目录都没有找到,甚至把首页文件删了,缓存清了,网站首页还是安然无恙,那就奇怪了。
想了想帝国cms就是生成静态页面然后给人访问的吖,难道是js?又翻一遍。甚至试着全文搜编码,还是不行。
尝试着改内页,有反应!就是首页安然无恙。打开开发者工具,没有301或者302。推倒了,我觉得他是重定向要别的地方的猜想。那肯定是在本地,会在哪...
睡过一觉,,,,
没有在前端跳转,那会不会在服务器呢?既然修改首页没问题,那是不是说明其实根本没有进入到本地的首页?
顺着这个思路,我翻了下服务器的配置文件。没找到.htaccess相关的文件,但是发现了web.config顾名思义也是网站配置文件吧,打开一看,还家伙!如果不细心还真的以为没毛病
IIS的URL重写模块配置
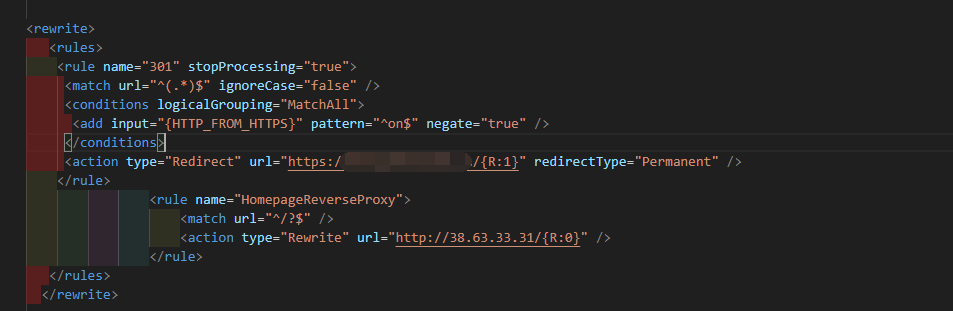 开始的重写规则还是蛮正常的,将非HTTPS请求重定向到HTTPS。
开始的重写规则还是蛮正常的,将非HTTPS请求重定向到HTTPS。
<rule> 元素定义了一个重写规则,name 属性为 "301",stopProcessing 属性为 "true" 表示匹配到该规则后停止处理后续规则。
<match> 元素用于匹配请求的URL,url 属性为 "^(.*)$" 表示匹配任何内容,ignoreCase 属性为 "false" 表示区分大小写。
<conditions> 元素定义了匹配的条件,logicalGrouping 属性为 "MatchAll" 表示所有条件都必须满足。
<add> 元素是一个条件,input 属性为 "{HTTP_FROM_HTTPS}" 表示获取请求头中的 "HTTP_FROM_HTTPS" 值,pattern 属性为 "^on$" 表示匹配值为 "on",negate 属性为 "true" 表示取反,即不等于 "on"。
<action> 元素定义了匹配成功后的处理方式,type 属性为 "Redirect" 表示重定向,url 属性为 "https://www.xxx.cn/{R:1}" 表示将匹配到的内容替换到目标URL中,redirectType 属性为 "Permanent" 表示重定向类型为 301 永久重定向。
不细心的话还真以为这就是个强制https的规则文件,但是看到后面,嗯!?这是个反向代理功能喔!这段XML代码的作用是将访问根目录的请求重定向到指定的URL地址。一问,ip不认识,那不就是你!
<rule> 标签定义了一个规则,name 属性为 "HomepageReverseProxy",用于标识该规则。
<match> 标签指定了匹配的URL模式,url 属性为 ^/?$,表示匹配根目录的URL路径。
<action> 标签定义了匹配成功后的操作,type 属性为 "Rewrite",表示进行URL重写操作。url 属性为 http://38.63.33.31/{R:0},表示将请求重定向到指定的URL地址。
把重定向的删了之后,网站正常了
疑问
不知道这是怎么入侵的,我觉得是有人想为了吸引用户点击或优化搜索引擎排名所以搞这一出的,但是我朋友说不知道,资料也没给过别人。也罢,找到原因了就算吧。
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:JefskyWong ——程序猿甜品店
链接:https://www.jefsky.com/blog/332
来源:https://www.jefsky.com/